下载没看上去这么简单
动机
如今,我们实际上并不关心网络下载的内部结构或细节。大多数情况下,我们单击浏览器上的链接并等待进度条完成。
如果我们觉得下载时间太长,通常是以太网速度受到指责。但是,我们从未想过该进度条下方使用的协议。即使对于实际需要实现某种下载代码的程序员,每种语言也总是有高级库。需要HTTPS吗?在您的 URL 前添加 https://,想要多个连接?轻触那个开关,库会为你做所有肮脏的工作。
好吧,直到最近,我也是这些人中的一员。在工作中,我们需要为一个大项目下载数百个依赖项。由于开发速度很快,每个人每天至少需要更新一次。由于依赖项的数量庞大且每个项的发布频率很高,同事抱怨公司聊天室的更新时间过长并不是一个不寻常的景象。我应该调查为什么它需要这么长时间并尝试优化。
现在我们不想更换基础设施,所以如果有的话,所有的优化都会发生在软件方面。使用的下载模式为HTTPS+并行下载。所以通常情况下,我对下载模型性能的不同组合进行了一些测试,我将在下面尝试重新创建。
TCP/IP 模型有四层:链路层、互联网层、传输层和应用层。但是由于我们不希望对基础架构进行任何更改,因此三个低级别层不在考虑范围中。对于应用层,我们可以控制 SSL 和并行/串行下载。
测试环境搭建
对于服务器,我使用我的一台笔记本电脑和 Apache 网络服务器。 首先,我们需要为我们的服务器启用 https。 通常情况下,ssl 证书的价格为数百美元。 但是为了测试,我们将使用自定义的 openssl。 笔记本电脑安装的ArchLinux自带了 openssl。 要生成证书,请运行
openssl req -new -x509 -nodes -out /srv/http/ssl.crt -keyout /srv/http/ssl.key -days 365
是的,我们将密钥和证书都存储在服务器根目录中,但这不是生产环境,只是为了测试。 之后我们将会删除这个目录。 在/etc/httpd/conf/httpd.conf里取消注释这些行之后:
LoadModule ssl_module modules/mod_ssl.so
LoadModule socache_shmcb_module modules/mod_socache_shmcb.so
Include conf/extra/httpd-ssl.conf
在/etc/httpd/conf/extra/httpd-ssl.conf里增加 SSLCertificateFile和SSLCertificateKeyFile的配置, 服务器就已经准备好相应HTTPS和HTTP的请求了。
对于相关的测试文件,我们将使用一些生成的文件。 为了生成这些文件,我编写了这个方便的脚本:
#!/bin/bash
for ((i=0; i<=$3; i++))
do
dd if=/dev/zero of=$1$i.img bs=1024 count=0 seek=$2
done
./dd_create.sh large 10000 100 将会生成100个大小为10000KB的文件,命名为: large1.img, large2.img …
在我运行 ./dd_create.sh small 1 100 和 ./dd_create.sh large 10000 100 后我就有了100个1KB和100个9.8MB的文件,我们可以开始测试了!
Test
在客户端,我们将使用 ruby 来分析速度。 这是我写的简单脚本:
require 'typhoeus'
def start_download(file_size, count)
time = Time.now
(1..count).each do |i|
req = Typhoeus::Request.new("http://192.168.5.21/#{file_size}#{i}.img")
req.on_complete do |response|
puts response.code.to_s unless response.success?
end
req.run
end
puts "#{file_size} sequential: #{Time.now - time}"
hydra = Typhoeus::Hydra.new
requests = (0..count).map do |i|
req = Typhoeus::Request.new("http://192.168.5.21/#{file_size}#{i}.img")
req.on_complete do |response|
puts response.code.to_s unless response.success?
end
req
end
requests.each { |request| hydra.queue(request) }
time = Time.now
hydra.run
puts "#{file_size} parallel: #{Time.now - time}"
end
start_download 'small', 100
start_download 'large', 20
typhoeus 是一个方便的 ruby libcurl封装,它默认支持并行下载。 代码非常简单,我从工作中学到的一件事是你必须确保您实际下载了文件而不是一些错误页面。 服务器在并行下载时返回 5XX 错误是很常见的。 无论如何,这是输出:
ruby parallel-vs-sequential.rb
small sequential: 0.436194286
small parallel: 0.096753443
large sequential: 17.951012144
large parallel: 20.063457664
很有趣,不是吗。 在小文件上,并行下载大大优于串行。 但是在大文件上,并行比串行慢! 我预计的是串行和并行具有相同的性能。 只有一根物理电缆,所以无论你如何下载,速度都应该是一样的。 好吧,仅当您将 tcp 视为流时。 对于流,这是真的。 因为水可以无限分割(到某种程度上),只要管道的总面积恒定,一根管道或一百根管道(速度恒定),流量就保持不变。 问题是,从表面上看,Tcp 看起来像一个流协议,但实际上,它不是。 数据包是离散的,Tcp 更像是气动管(pneumatic tube)而不是水管。

在小文件情况下,内容很少,它们可以放入一个 Tcp 数据包中。 这意味着数据的总大小与整个网络链路的体积是在同个数量级的。 因此,对于串行下载,我们向服务器发送一个数据包,要求返回一个数据包。 然后直到我们收到了前一个数据包,我们才开始要求下一个。 我们需要等待上一个数据包,然后再请求下一个。
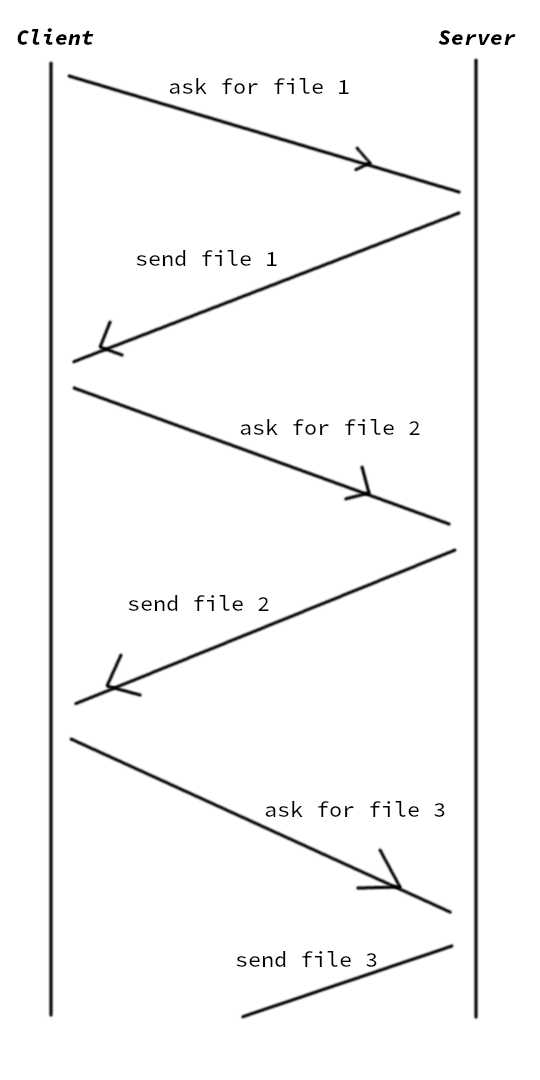
在并行下载时,我们首先发送所有请求。 服务器在收到所有请求后,通过将所有请求的文件发回进行响应。 更像是这张图:

因此,并行方式可以充分利用网络,而不像串行下载,整条链路上只有一个数据包在进行传输。 但是对于较大的文件,每个文件需要数千个数据包才能传输。 不会有时间等待数据包的回传,只有在这种情况下,Tcp 就像一个流。 但是,嘿,在大文件上,并行比串行慢! 那是因为 Tcp 有另一个特性,拥塞控制。 旨在避免数据包冲突,一旦检测到链路过于拥挤,Tcp 会自动降低发送数据包的速度。 一旦流量不再拥挤,它会再次开始以高频率发送。 问题是,即使在同一台机器上,每个 Tcp 流不知道其他流的存在。 加速过程需要一些时间。 所以在并行模式下,每个流都处于慢速以避免交通 -> 交通干净,加速 -> 大流量,减速 -> 再次加速 …
加速时间是大文件情况下并行比串行慢的原因。
那么在HTTPS下是怎么样的呢?
为了测试 HTTPS,我们需要对我们的 ruby 代码做一些修改。 因为我们使用自定义签名证书,默认情况下 curl 拒绝建立到自定义证书服务器的连接。 对此的解决方法是将 --insecure 传递给 curl。 但是,我似乎无法将这个论点从 typhoeus 传递给它的底层 libcurl。 所以我直接使用 curl 代替。 由于这引入了新的开销,我们也需要重新运行 HTTP 测试。 无论如何,这是修改后的代码:
def start_download(file_size, count)
time = Time.now
(1..count).each do |i|
system "curl --insecure --output - https://192.168.5.21/#{file_size}#{i}.img"
end
puts "#{file_size} sequential: #{Time.now - time}"
list = (1..count).map do |i|
"curl --insecure --output - https://192.168.5.21/#{file_size}#{i}.img &"
end
list.push "wait"
time = Time.now
system list.join
puts "#{file_size} parallel: #{Time.now - time}"
end
def start_download_http(file_size, count)
time = Time.now
(1..count).each do |i|
system "curl --output - http://192.168.5.21/#{file_size}#{i}.img"
end
puts "#{file_size} sequential: #{Time.now - time}"
list = (1..count).map do |i|
"curl --output - http://192.168.5.21/#{file_size}#{i}.img &"
end
list.push "wait"
time = Time.now
system list.join
puts "#{file_size} parallel: #{Time.now - time}"
end
start_download 'small', 100
start_download 'large', 20
start_download_http 'small', 100
start_download_http 'large', 20
运行后输出如下:
small sequential: 3.318103766
small parallel: 0.146631044
large sequential: 43.611648222
large parallel: 42.185408598
# now begin the http tests
small sequential: 1.094627036
small parallel: 0.072095248
large sequential: 43.989152202
large parallel: 43.201014222
嗯,对于小文件,HTTPS 比 HTTP 慢 3 倍。但是在大文件上,它们是相同的的。很容易解释为什么 HTTPS 在小文件上速度较慢,HTTPS 引入了 SSL 握手,这是一个很大的开销。此外,所有通过 HTTPS 传输的数据都是加密的,这意味着需要做更多的工作。但是您可能想知道为什么它们在大文件上具有相同的速度,加密的开销难道不是和体积成线性关系的吗?是的,但是只在认为计算机是一台机器的情况下。但是,计算机不是一台机器,至少在这种情况下不是这样。加密过程发生在 CPU 上,数据发送发生在以太网卡上。除了必须首先加密的第一段数据之外,后续的数据包可以更早地加密。由于CPU比数据包发送快很多,所以在以太网卡发送第一个数据包的时间范围内,CPU已经成功加密了第二、第三和第四个数据包。所以以太网卡只需要等待第一个数据包的加密时间。由于传输每个大文件需要发送 10000 个数据包,因此一个数据包的加密时间无关紧要。在小文件上,只有一个数据包,以太网卡必须等待。
此外,在 HTTPS 上,并行大文件下载比顺序下载略快。我猜这是因为 20 个连接的第一个数据包是并行加密的,而在串行下载时它们是串行加密的。 19个数据包的加密时间就节省了。我只是猜测,可能与网络的整体不稳定有关(我在本地网络上,但您知道,网络)。
嗯,他们在学校教计算机网络是有原因的。希望你觉得这篇文章很有趣。