Ruby Ractor and Parallelism in Interpreted Languages
Ractor
One of the major feature of Ruby 3.0 is the introduction of ‘ractor’. Ractor is a new concurrent abstraction for Ruby. Unlike Ruby threads, ractors can run in parallel. Due to the Ruby Global Virtual Machine Lock(GVL), even each Ruby thread is mapped to native thread, there can only be one active thread running. But after the introduction of ractor, there can be multiple GVL, each ractor has one. That’s why ractors can have parallel execution.
The introduction of ractor enables Ruby to achieve true parallelism, while using one interpreter. Before we dive into the ractor implementation, I’d like to first talk about why Ruby has GVL in the first place.
Global VM Lock
GVL, or GIL(Global Interpreter Lock) in Python. It’s an interpreter wide lock that ensures only one thread is executing at any given time. It exists for the ease of interpreter development. To understand why only interpreted languages have this while other languages doesn’t, we need to know what interpreter does. Ruby allows dynamic adding of instance/class variables of classes/modules, it stores this information inside a table. Now, if two threads are modifying this table, data race will happen. The other thing interpreter does is garbage collection. Information about garbage collection is stored in ‘Object Space’, garbage collector will iterate through this space, delete every object that is unreferenced. Now if while one thread triggered garbage collector, but the other thread is still creating objects, data race will also happen.
So if you have a GVL, you don’t have to worry about the above problems. Languages like Java doesn’t allow modifying of class variables in runtime. And information about garbage collection is not stored in a centralised space, it’s stored separate on each object itself.
Parallelism before Ractor
To achieve parallelism, Ruby on Rails spawns several new Ruby process. Since each Ruby process has its own GVL. But we now have multiple interpreters, this makes our program inefficient. Similarly, Python’s Flask uses this approach too. As for the Node.js, it also spawns new Js engines. But Js doesn’t have GVL, since it doesn’t have threads.
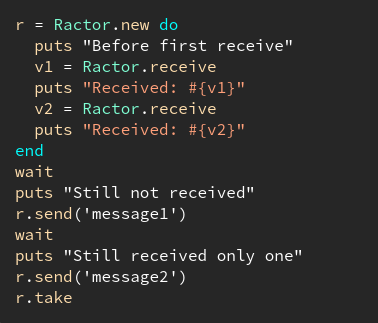
How Ractor solves these problems
Our major problems is data race of instance/class variable table and ‘Object Space’. The other problem is you can’t associate mutex with Ruby object so synchronous writing to object can also lead to race condition.
Ractor ‘solves’ data race of instance/class variable by restricting access to only main Ractor. One thread ain’t gonna create data race, hmm?
And for garbage collection, everytime garbage collector is running, all executions of other Ractors is suspended.
Third, objects aren’t shared between Ractors. Ractors can only access objects that is either frezee or being one of “Special shareable objects”(Ractor itself). To share mutable objects between Ractors, you need to either ‘move’ it(thus making it unavailable in original Ractor) or deep copy it. Basically limited communication methods to inter-process ones.
So Ractor ‘solves’ these problems by not solving them! Yes, you get real parallelism without multiple processes. But you can only use it like you’re having multiple processes! In other words, Ruby Ractor is not parallel threads, it’s more like “Process with Benefits”. You use it like process, while not committing to the cost of creating new interpreter. :P
Is it easy to use?
There are many examples about Ractor on official documentation. It almost makes me believe Ractor is so powerful that I can convert my production code to using Ractor and achieve 10X performance within a day. Well, due to the limitations I stated above, it’s extremely hard to converting existing code base to Ractor. Considering a class for ranking some objects. You may have a hash to associate value to priority. Now suppose it’s a generic class, the actually supported ranking object value needs to be determined at runtime. This means that hash will need to be modified at runtime. A common way to do this is to use lazy initialization to update hash when needed. But our Ractor expected class variables to be frozen, so we need to freeze the hash before hand. However we don’t know what should be in the hash before we starting ranking the objects! The usages of autoload, ||= and monkey patching make converting existing programs to use Ractor near impossible. Especially if you’re using third party Gems. The program archtectiture have to be alternated before anyone can employ Ractors.
If everyone writes Ruby code with Ractors in mind, it will be much easier to take benefits from Ractor. However, Ractor only upstreamed in Ruby 3.0 and most Ruby code are written in 2.x era. Re-writing the humongous code base would take a long time. The current experiemental status of Ractor means the effort won’t happen soon.
Conclusion
I’m not saying Ractor is a failure, it’s a nice feature to have. It’s a step towards fine grained lock, by separating where really requires a lock from the rest of the interpreter. To implement Ractor on a language that designed to have GVL is a challenge itself.