Quirks of Downloading
Motivation
These days, we don’t actually care about the internals or details of network downloading. Most of the time, we click a link on the browser and wait for the progress bar to finish.
If we feel the downloading is taking too long, usually Ethernet speed gets the blame. However, we never thought about the protocols used underneath that progress bar. Even for programmers that actually needs to implement some sort of downloading code, there are always high level libraries for every language. Needs HTTPS? Add https:// in front of your URL, want multiple connections? Flick that switch on and the library does all the dirty work for you.
Well, I’m one of those guys, until recently. In work, we need to download hundreds of dependencies for one big project. Since the development is going in fast pace, everyone would update them at least once per day. Due to the sheer volume of the dependencies and the high frequency of each’s release, complains of colleagues about the updating taking too long on corp chat room aren’t an unusual sight. It’s happened that I should investigate why it’s taking so long and try to optimize.
Now we don’t want to replace the infrastructures, so all the optimizations would happen in software side if there is any. The downloading model in use is HTTPS + parallel downloading. So normally, I did some tests about different combinations of downloading model’s performance, which I’ll try to re-create below.
TCP/IP model has four layers: Link layer, Internet layer, Transport layer and Application layer. But since we don’t want any change to the infrastructures, three low level layers are out of table. For application layer, we can control SSL and parallel/sequential downloading.
Test Environment Setup
For server, I’m using one of my laptop with apache web server. First we need to enable https for our server. Normally, ssl certificate is brought for hundreds of dollars. But for test, we will be using a custom one with openssl. The laptop is installed with ArchLinux and openssl comes with the system. To generate a certificate, run
openssl req -new -x509 -nodes -out /srv/http/ssl.crt -keyout /srv/http/ssl.key -days 365
Yeah, we store both key and cert on the server root, but this isn’t in production environment, and it’s for test anyway. We’ll nuke this directory afterwards. After uncommenting these lines in /etc/httpd/conf/httpd.conf:
LoadModule ssl_module modules/mod_ssl.so
LoadModule socache_shmcb_module modules/mod_socache_shmcb.so
Include conf/extra/httpd-ssl.conf
and added SSLCertificateFile SSLCertificateKeyFile in /etc/httpd/conf/extra/httpd-ssl.conf, the server is ready to respond to both HTTP and HTTPS request.
For the test file concerned, we will be using some dummies. To generate some dummies files, I wrote this handy script:
#!/bin/bash
for ((i=0; i<=$3; i++))
do
dd if=/dev/zero of=$1$i.img bs=1024 count=0 seek=$2
done
./dd_create.sh large 10000 100 will create 100 files sized 10000KB named large1.img, large2.img …
so after I ran ./dd_create.sh small 1 100 and ./dd_create.sh large 10000 100 I got one hundred 1KB files and one hundred 9.8MB files. We’re ready to go!
Test
On client, we’ll be using ruby to profile the speed. This is the simple script I wrote:
require 'typhoeus'
def start_download(file_size, count)
time = Time.now
(1..count).each do |i|
req = Typhoeus::Request.new("http://192.168.5.21/#{file_size}#{i}.img")
req.on_complete do |response|
puts response.code.to_s unless response.success?
end
req.run
end
puts "#{file_size} sequential: #{Time.now - time}"
hydra = Typhoeus::Hydra.new
requests = (0..count).map do |i|
req = Typhoeus::Request.new("http://192.168.5.21/#{file_size}#{i}.img")
req.on_complete do |response|
puts response.code.to_s unless response.success?
end
req
end
requests.each { |request| hydra.queue(request) }
time = Time.now
hydra.run
puts "#{file_size} parallel: #{Time.now - time}"
end
start_download 'small', 100
start_download 'large', 20
typhoeus is a handy ruby libcurl wrapper for our case, it supports parallel download by default. The code is pretty simple, one thing I’ve learned from work is that you have to ensure you actually downloaded the file not some error pages. It’s common for server to return 5XX error on parallel download. Anyway, here is the output:
ruby parallel-vs-sequential.rb
small sequential: 0.436194286
small parallel: 0.096753443
large sequential: 17.951012144
large parallel: 20.063457664
Interesting, isn’t it. On small files, parallel outperforms sequential by a large margin. But on large files, parallel is slower than sequential! I’d expect both sequential and parallel have the same performance. There is only one physical cable so no matter how you download the speed should be the same. Well, only if you think tcp as stream. For stream, that’s true. Because water can be indifinitely divided (to some extent), the flow rate stays the same as long as the total area of the pipe, one pipe or one hundred pipes(velocity being constant). The thing is, on the surface, Tcp looks like a stream protocol, but actually, it’s not. Packets are discrete, Tcp is more like pneumatic-tube than water pipes.

In small file case, the content size is tiny, they can be fit into one Tcp packet. That means the total size of the data is proportional to the volume of whole network link. So for the sequential download, we send one packet to server asking for one packet back. Then after we’ve received the one back, we then start to ask for the next one. We’ll need to wait for the previous one before ask for the next.
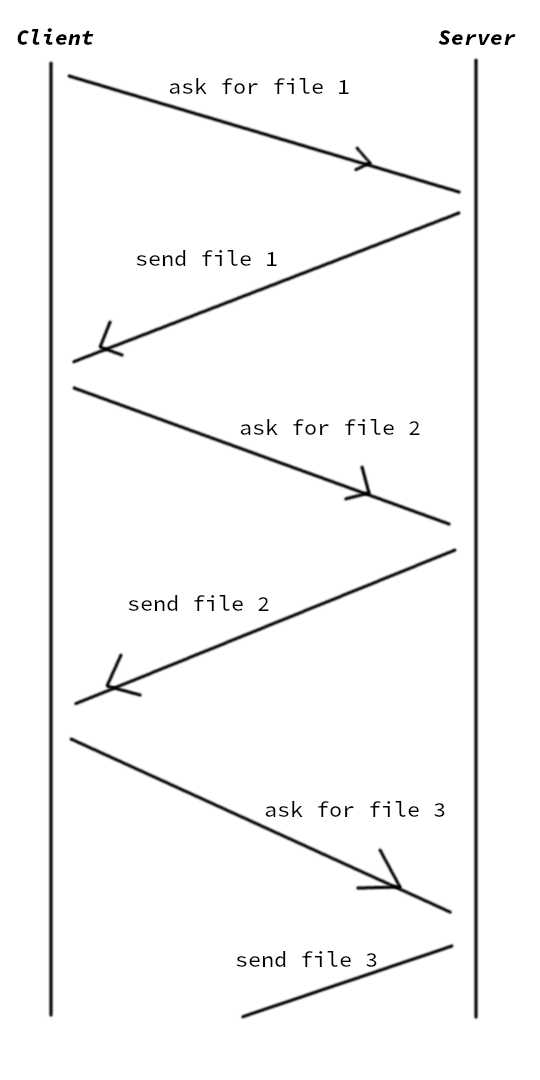
On parallel download, we send all our requests first. The server, upon receiving all the requests, responded by sending all the requested files back. It’s more like this image:

So the parallel way can fully utilize the network while there is only one packet on the link for the sequential. But for the larger files, one file each needs thousands of packets to transfer. There is no time spent waiting, only in this scenario Tcp acts like a stream. But hey, parallel is slower than sequential on large files! That’s because Tcp has another quirk, Congestion Control. Designed to avoid collision of packets, once the link is detected too crowded, Tcp automatically slower the speed of sending packets. Once the traffic lightens, it starts to send again in a high frequency. The thing is, each Tcp stream doesn’t know the others, even on a same machine. And the speeds up process takes some time. So in parallel mode, each stream is in slow speed to avoid traffic -> traffic clean, speeds up -> heavy traffic, slow down -> speeds up again …
The speed up time is the reason parallel slower than sequential on large file case.
Now what about HTTPS?
To test HTTPS, we need to do some modification to our ruby code. Because we’re using a custom signed certification, curl by default refused to establish connection to a custom certificated server. A workaround for this is to pass --insecure to curl. However, it seems I’m unable to pass this argument from typhoeus to it’s underlying libcurl. So I’m using curl directly instead. Since this introduced new overhead, we’ll need to re-run HTTP test too. Anyway, here is the modificated code:
def start_download(file_size, count)
time = Time.now
(1..count).each do |i|
system "curl --insecure --output - https://192.168.5.21/#{file_size}#{i}.img"
end
puts "#{file_size} sequential: #{Time.now - time}"
list = (1..count).map do |i|
"curl --insecure --output - https://192.168.5.21/#{file_size}#{i}.img &"
end
list.push "wait"
time = Time.now
system list.join
puts "#{file_size} parallel: #{Time.now - time}"
end
def start_download_http(file_size, count)
time = Time.now
(1..count).each do |i|
system "curl --output - http://192.168.5.21/#{file_size}#{i}.img"
end
puts "#{file_size} sequential: #{Time.now - time}"
list = (1..count).map do |i|
"curl --output - http://192.168.5.21/#{file_size}#{i}.img &"
end
list.push "wait"
time = Time.now
system list.join
puts "#{file_size} parallel: #{Time.now - time}"
end
start_download 'small', 100
start_download 'large', 20
start_download_http 'small', 100
start_download_http 'large', 20
execute the code we got the following result:
small sequential: 3.318103766
small parallel: 0.146631044
large sequential: 43.611648222
large parallel: 42.185408598
# now begin the http tests
small sequential: 1.094627036
small parallel: 0.072095248
large sequential: 43.989152202
large parallel: 43.201014222
Hmm, on small files, HTTPS is 3x slower than HTTP. But on large files, they’re on pair. It’s easy to explain why HTTPS is slower on small files, HTTPS introduces SSL handshake which is a significant overhead. Besides, all data transfer through HTTPS are encrypted which means more work needs to be done. But you maybe wonder why they have the same speed on large files, doesn’t the encryption introduces liner overhead? Well, if you think computer as a single machine, it is. But, computer isn’t a single machine, at least on this scenario. The encryption process happens on CPU, the data sending happens on Ethernet card. Apart for the first segment of data, which has to be encrypted first, consequent packets can be encrypted earlier. Because CPU is multitude faster than network speed, in the time frame of Ethernet card sending first packet, CPU has managed to encrypted packet two, three and four. So Ethernet card only need to wait one encryption time. Since large files each require 10000 packets to sent, that one packet encryption time doesn’t matter. On small files, there is only one packet, Ethernet card has to wait.
Also, on HTTPS, parallel large file downloading is slightly faster than sequential. I guess it’s because the first packets of 20 connection are encrypted parallelly, whereas on sequential downloading they’re encrypted sequentially. 19 packets' encryption time save. I’m just guessing, could have something to do with the overall instability of network(I’m on a local network, but you know, network).
Well, they teach networking at school for a reason. Hope you find this article interesting.