Detect Cycle When Analyzing Dependencies
The dependencies of a package can be viewed as a directed graph. It does not have to be a tree, as sub-dependencies can be shared. However, it is important to ensure that there are no circular dependencies. Circular dependencies can cause dynamic library builds to fail, and in the worst case, there are cyclic references in your project. Introducing memory leak in reference counting based garbage collectors.
There are thousands of articles online about finding cycles in directed and indirected graphs. But they all explain the algorithm in a highly abstracted way, simpley translating the methods they described will not solve the problem of finding and reporting circular dependencies in the resolving process.
Difference
Input and Output can determine which algorithm to use or how to implement a particular algorithm. In the Algorithm & Data Structure 101 style online articles, the input is one or more top level nodes. And in our case, a list of direct sub-dependencies of the package. The difference is the output, the goal of package manager is to installing all dependencies, the optimal structure is an array or a list. However, the introductary articles only show us how to check if there is a cycle.
DFS But With A Little Twist
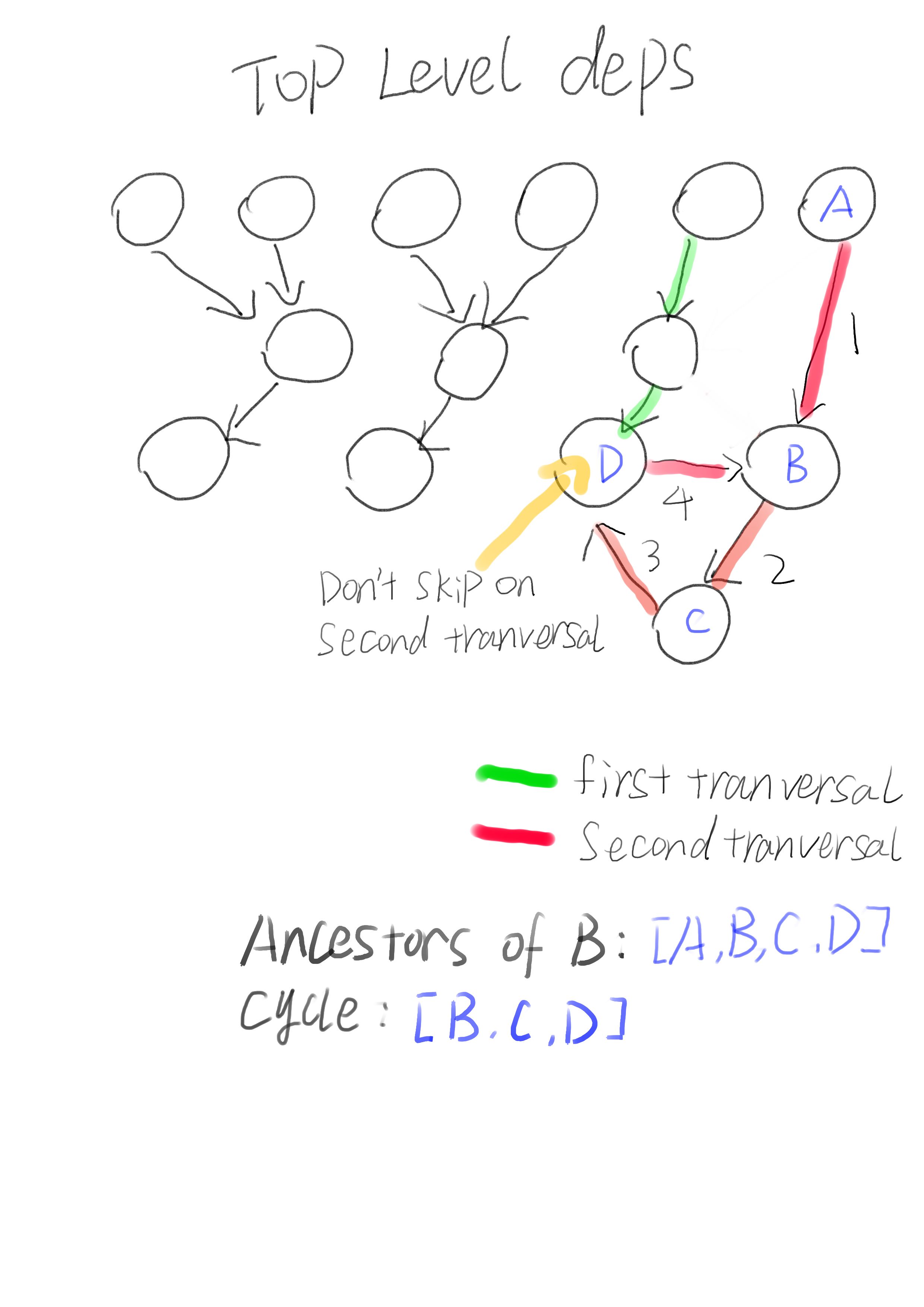
To figure out all the dependencies, we would use BFS or DFS anyway. I don’t want to change the original code too much. So instead of maintaining a stack to track the ancestors of each nore, I took inspiration from another cycle detection algorithm: Rocha–Thatte cycle detection algorithm. Instead of keeping a stack of ancestors, I pass the ancestors to each nodes at each iteration. If the set of ancestors passed a node contains itself, then we find a cycle.
The original code looks like this:
dependencies = getDependencies();
resolved_dependencies = Set.new();
while (!dependencies.empty()) {
dependency = dependencies.pop();
find_and_validate(dependency);
resolved_dependencies.append(dependency);
sub_dependencies = dependency.getSubDependencies().
select(|dep| return !resolved_dependencies.contain(dep));
dependencies.append(sub_dependencies);
}
return resolved_dependencies.map(|dep| return dep;);
After adding cycle detection:
dependencies = getDependencies();
resolved_dependencies = Set.new();
while (!dependencies.empty()) {
dependency = dependencies.pop();
find_and_validate(dependency);
resolved_dependencies.append(dependency);
sub_dependencies = dependency.getSubDependencies();
for (dep in sub_dependencies) {
if (dependency.ancestors.include(dep)) {
report_cycle(dependency, dep, resolved_dependencies);
} else {
dep.ancestors.merge(dependency.ancestors);
}
}
sub_dependencies.select!(|dep| return !resolved_dependencies.contain(dep));
dependencies.append(sub_dependencies);
}
return resolved_dependencies.map(|dep| return dep;); // return array
The only change to original code logic is that we filter already resolved dependencies later. Since dependencies in the cycle could be resolved in the previous iteration, we would potentially miss the cycle if we skipped the resolved dependencies. Instead, we check the cycle first and then filter out dependencies that have already been resolved.
This algorithm can detect cycle, but it cannot determine exactly which dependencies are in the cycle. This is because not all ancestors are necessary in the cycle. To figure out the cycle, we use report_cycle to perform another Depth First Transversal. This time, we can safely ignore any dependencies not contained in resolved_dependencies. Any dependency not included in the resolved_dependencies set has not been visited before and thus not part of the cycle.
fn report_cycle(cycle_end, cycle_start, resolved_dependencies) {
cycle = find_cycle(cycle_end, cycle_start, resolved_dependencies, []);
raise cycle;
}
fn find_cycle(cycle_end, cycle_start, resolved_dependencies, cycle) {
if (cycle_end == cycle_start) {
return cycle;
}
sub_dependencies = cycle_start.getSubDependencies();
for (dep in sub_dependencies) {
if (!resolved_dependencies.include(dep)) {
continue;
}
result = find_cycle(cycle_end, dep, resolved_dependencies, cycle.clone().append(dep));
if (result) {
return result;
}
}
return [];
}
And it’s pretty easy to turn off the cycle detection too, I can use a flag to skip the execution of
for (dep in sub_dependencies) {
if (dependency.ancestors.include(dep)) {
report_cycle(dependency, dep, resolved_dependencies);
} else {
dep.ancestors.merge(dependency.ancestors);
}
}
in the main loop, and cycle detection functionality is disabled.
Performance
I tested the code on a project with 2600 total dependencies, the total dependencies resolution time changed from 2.2s to 2.3s. After disabling the detection, the performance penalty is negletable.